Data science is the domain of study that deals with vast volumes of data using modern tools and techniques to find unseen patterns, derive meaningful information, and make business decisions. Data science uses complex machine learning algorithms to build predictive models. The data used for analysis can come from many different sources and presented in various formats.
Data Science Lifecycle
Data Science Lifecycle revolves around the use of machine learning and different analytical strategies to produce insights and predictions from information in order to acquire a commercial enterprise objective.
The complete method includes a number of steps like data cleaning, preparation, modelling, model evaluation, etc. It is a lengthy procedure and may additionally take quite a few months to complete. So, it is very essential to have a generic structure to observe for each and every hassle at hand.
Let us understand what is the need for Data Science?
Earlier data used to be much less and generally accessible in a well-structured form, that we could save effortlessly and easily in Excel sheets, and with the help of Business Intelligence tools data can be processed efficiently. But Today we used to deals with large amounts of data like about 3.0 quintals bytes of records is producing on each and every day, which ultimately results in an explosion of records and data. According to recent researches, It is estimated that 1.9 MB of data and records are created in a second that too through a single individual.
So this a very big challenge for any organization to deal with such a massive amount of data generating every second. For handling and evaluating this data we required some very powerful, complex algorithms and technologies and this is where Data science comes into the picture.
1. Business Understanding: The complete cycle revolves around the enterprise goal. What will you resolve if you do not longer have a specific problem? It is extraordinarily essential to apprehend the commercial enterprise goal sincerely due to the fact that will be your ultimate aim of the analysis. After desirable perception only we can set the precise aim of evaluation that is in sync with the enterprise objective. You need to understand if the customer desires to minimize savings loss, or if they prefer to predict the rate of a commodity, etc.
2. Data Understanding: After enterprise understanding, the subsequent step is data understanding. This includes a series of all the reachable data. Here you need to intently work with the commercial enterprise group as they are certainly conscious of what information is present, what facts should be used for this commercial enterprise problem, and different information. This step includes describing the data, their structure, their relevance, their records type. Explore the information using graphical plots. Basically, extracting any data that you can get about the information through simply exploring the data.
3. Preparation of Data: Next comes the data preparation stage. This consists of steps like choosing the applicable data, integrating the data by means of merging the data sets, cleaning it, treating the lacking values through either eliminating them or imputing them, treating inaccurate data through eliminating them, additionally test for outliers the use of box plots and cope with them. Constructing new data, derive new elements from present ones. Format the data into the preferred structure, eliminate undesirable columns and features. Data preparation is the most time-consuming but arguably the most essential step in the complete existence cycle. Your model will be as accurate as your data.
4. Exploratory Data Analysis: This step includes getting some concept about the answer and elements affecting it, earlier than constructing the real model. Distribution of data inside distinctive variables of a character is explored graphically the usage of bar-graphs, Relations between distinct aspects are captured via graphical representations like scatter plots and warmth maps. Many data visualization strategies are considerably used to discover each and every characteristic individually and by means of combining them with different features.
5. Data Modeling: Data modeling is the coronary heart of data analysis. A model takes the organized data as input and gives the preferred output. This step consists of selecting the suitable kind of model, whether the problem is a classification problem, or a regression problem or a clustering problem. After deciding on the model family, amongst the number of algorithms amongst that family, we need to cautiously pick out the algorithms to put into effect and enforce them. We need to tune the hyperparameters of every model to obtain the preferred performance. We additionally need to make positive there is the right stability between overall performance and generalizability. We do no longer desire the model to study the data and operate poorly on new data.
6. Model Evaluation: Here the model is evaluated for checking if it is geared up to be deployed. The model is examined on an unseen data, evaluated on a cautiously thought out set of assessment metrics. We additionally need to make positive that the model conforms to reality. If we do not acquire a quality end result in the evaluation, we have to re-iterate the complete modelling procedure until the preferred stage of metrics is achieved. Any data science solution, a machine learning model, simply like a human, must evolve, must be capable to enhance itself with new data, adapt to a new evaluation metric. We can construct more than one model for a certain phenomenon, however, a lot of them may additionally be imperfect. The model assessment helps us select and construct an ideal model.
7. Model Deployment: The model after a rigorous assessment is at the end deployed in the preferred structure and channel. This is the last step in the data science life cycle. Each step in the data science life cycle defined above must be labored upon carefully. If any step is performed improperly, and hence, have an effect on the subsequent step and the complete effort goes to waste. For example, if data is no longer accumulated properly, you’ll lose records and you will no longer be constructing an ideal model. If information is not cleaned properly, the model will no longer work. If the model is not evaluated properly, it will fail in the actual world. Right from Business perception to model deployment, every step has to be given appropriate attention, time, and effort.
Relation between data science and machine learning
Data science and machine learning are closely related fields, and they often go hand in hand, with machine learning being a subset of data science. Here's an overview of their relationship:
Data Science Overview:
Definition: Data science is a multidisciplinary field that uses scientific methods, processes, algorithms, and systems to extract insights and knowledge from structured and unstructured data.
Components: Data science encompasses various components, including data cleaning, exploration, visualization, statistical analysis, and predictive modeling.
Machine Learning Overview:
Definition: Machine learning is a subset of artificial intelligence that focuses on the development of algorithms that enable computers to learn patterns and make predictions or decisions without being explicitly programmed.
Components: Machine learning includes tasks such as supervised learning, unsupervised learning, reinforcement learning, and deep learning. It involves training models on data to recognize patterns and make predictions or decisions.
Relationship between Data Science and Machine Learning:
Data as the Foundation: Data science relies on data to derive insights and solve problems. Machine learning, in turn, uses algorithms to learn from and make predictions or decisions based on that data.
Predictive Modeling: Machine learning is often a crucial component of data science, especially in predictive modeling. Data scientists use machine learning algorithms to build models that can predict future outcomes or classify data into different categories.
Tools and Techniques: Data scientists often use machine learning tools and techniques to analyze and interpret data. Machine learning algorithms help in identifying patterns, trends, and relationships within the data that may not be apparent through traditional statistical methods.
Iterative Process: Data science is often an iterative process where machine learning models are built, evaluated, and refined based on the results obtained. This iterative cycle contributes to the improvement of models and the overall data science process.
Common Tasks in Data Science and Machine Learning:
Exploratory Data Analysis (EDA): Both data science and machine learning involve exploring and understanding the data through techniques such as visualization and statistical analysis.
Feature Engineering: In both fields, selecting and engineering relevant features from the data is crucial for building effective models.
Model Evaluation: Both data scientists and machine learning practitioners need to assess the performance of their models, ensuring they generalize well to new, unseen data.
In summary, while data science is a broader field that encompasses various techniques for extracting insights from data, machine learning is a specific set of techniques within data science that focuses on building models capable of learning and making predictions or decisions. Data science provides the foundation, and machine learning is a powerful tool within the data scientist's toolkit.
Types Of Data – Nominal, Ordinal, Discrete and Continuous
The data is classified into four categories:
Nominal data.
Ordinal data.
Discrete data.
Continuous data.
Qualitative or Categorical Data
Qualitative or Categorical Data is data that can’t be measured or counted in the form of numbers. These types of data are sorted by category, not by number. That’s why it is also known as Categorical Data. These data consist of audio, images, symbols, or text. The gender of a person, i.e., male, female, or others, is qualitative data.
Qualitative data tells about the perception of people. This data helps market researchers understand the customers’ tastes and then design their ideas and strategies accordingly.
The other examples of qualitative data are :
What language do you speak
Favorite holiday destination
Opinion on something (agree, disagree, or neutral)
Colors
The Qualitative data are further classified into two parts :
Nominal Data
Nominal Data is used to label variables without any order or quantitative value. The color of hair can be considered nominal data, as one color can’t be compared with another color.
The name “nominal” comes from the Latin name “numen,” which means “name.” With the help of nominal data, we can’t do any numerical tasks or can’t give any order to sort the data. These data don’t have any meaningful order; their values are distributed into distinct categories.
Examples of Nominal Data :
Color of hair (Blonde, red, Brown, Black, etc.)
Marital status (Single, Widowed, Married)
Nationality (Indian, German, American)
Gender (Male, Female, Others)
Eye Color (Black, Brown, etc.)
Ordinal Data
Ordinal data have natural ordering where a number is present in some kind of order by their position on the scale. These data are used for observation like customer satisfaction, happiness, etc., but we can’t do any arithmetical tasks on them.
Ordinal data is qualitative data for which their values have some kind of relative position. These kinds of data can be considered “in-between” qualitative and quantitative data. The ordinal data only shows the sequences and cannot use for statistical analysis. Compared to nominal data, ordinal data have some kind of order that is not present in nominal data.
Examples of Ordinal Data :
When companies ask for feedback, experience, or satisfaction on a scale of 1 to 10
Letter grades in the exam (A, B, C, D, etc.)
Ranking of people in a competition (First, Second, Third, etc.)
Economic Status (High, Medium, and Low)
Education Level (Higher, Secondary, Primary)
Difference between Nominal and Ordinal Data
Nominal Data
Ordinal Data
Nominal data can’t be quantified, neither they have any intrinsic ordering
Ordinal data gives some kind of sequential order by their position on the scale
Nominal data is qualitative data or categorical data
Ordinal data is said to be “in-between” qualitative data and quantitative data
They don’t provide any quantitative value, neither can we perform any arithmetical operation
They provide sequence and can assign numbers to ordinal data but cannot perform the arithmetical operation
Nominal data cannot be used to compare with one another
Ordinal data can help to compare one item with another by ranking or ordering
Examples: Economic status, customer satisfaction, education level, letter grades, etc
Quantitative Data
Quantitative data can be expressed in numerical values, making it countable and including statistical data analysis. These kinds of data are also known as Numerical data. It answers the questions like “how much,” “how many,” and “how often.” For example, the price of a phone, the computer’s ram, the height or weight of a person, etc., falls under quantitative data.
Quantitative data can be used for statistical manipulation. These data can be represented on a wide variety of graphs and charts, such as bar graphs, histograms, scatter plots, boxplots, pie charts, line graphs, etc.
Examples of Quantitative Data :
Height or weight of a person or object
Room Temperature
Scores and Marks (Ex: 59, 80, 60, etc.)
Time
The Quantitative data are further classified into two parts :
Discrete Data
The term discrete means distinct or separate. The discrete data contain the values that fall under integers or whole numbers. The total number of students in a class is an example of discrete data. These data can’t be broken into decimal or fraction values.
The discrete data are countable and have finite values; their subdivision is not possible. These data are represented mainly by a bar graph, number line, or frequency table.
Examples of Discrete Data :
Total numbers of students present in a class
Cost of a cell phone
Numbers of employees in a company
The total number of players who participated in a competition
Days in a week
Continuous Data
Continuous data are in the form of fractional numbers. It can be the version of an android phone, the height of a person, the length of an object, etc. Continuous data represents information that can be divided into smaller levels. The continuous variable can take any value within a range.
The key difference between discrete and continuous data is that discrete data contains the integer or whole number. Still, continuous data stores the fractional numbers to record different types of data such as temperature, height, width, time, speed, etc.
Examples of Continuous Data :
Height of a person
Speed of a vehicle
“Time-taken” to finish the work
Wi-Fi Frequency
Market share price
Difference between Discrete and Continuous Data
Discrete Data
Continuous Data
Discrete data are countable and finite; they are whole numbers or integers
Continuous data are measurable; they are in the form of fractions or decimal
Discrete data are represented mainly by bar graphs
Continuous data are represented in the form of a histogram
The values cannot be divided into subdivisions into smaller pieces
The values can be divided into subdivisions into smaller pieces
Discrete data have spaces between the values
Continuous data are in the form of a continuous sequence
Examples: Total students in a class, number of days in a week, size of a shoe,
Example: Temperature of room, the weight of a person, length of an object,
UNIT 2 : STATISTICS AND PROBABILITY BASICS FOR DATA ANALYSIS
STATISTICS:
Mean, Median and Mode
Mean
In mathematics and statistics, the mean is the average of the numerical observations which is equal to the sum of the observations divided by the number of observations.
where,
=
arithmetic mean
=
number of values
=
data set values
Median
The median of the data, when arranged in ascending or descending value is the middle observation of the data i.e. the point separating the higher half to the lower half of the data.
To calculate the median:
Arrange the data in ascending or descending order.
an odd number of data points: the middle value is the median.
even number of data points: the average of the two middle values is the median.
=
an ordered list of values in the data set
=
number of values in data set
Mode
The mode of a set of data points is the most frequently occurring value.
For example:
5,2,6,5,1,1,2,5,3,8,5,9,5 are the set of data points. Here 5 is the mode because it’s occurring most frequently.
Variance and Standard Deviation
Variance
Mathematically and statistically, variance is defined as the average of the squared differences from the mean. But for understanding, this depicts how spread out the data is in a dataset.
The steps of calculating variance using an example:
Let’s find the variance of (1,4,5,4,8)
Find the mean of the data points i.e. (1 + 4 + 5 + 4 + 8)/5 = 4.4
Find the differences from the mean i.e. (-3.4, -0.4, 0.6, -0.4, 3.6)
Find the squared differences i.e. (11.56, 0.16, 0.36, 0.16, 12.96)
Find the average of the squared differences i.e. 11.56+0.16+0.36+0.16+12.96/5=5.04
The formula for the same is:
Standard Deviation
Standard deviation measures the variation or dispersion of the data points in a dataset. It depicts the closeness of the data point to the mean and is calculated as the square root of the variance.
In data science, the standard deviation is usually used to identify the outliers in a data set. The data points which lie one standard deviation away from the mean are considered to be unusual.
The formula for standard deviation is:
=
population standard deviation
=
the size of the population
=
each value from the population
=
the population mean
Population Data V/s Sample Data
Population data refers to the complete data set whereas sample data refers to a part of the population data which is used for analysis. Sampling is done to make analysis easier.
When using sample data for analysis, the formula of variance is slightly different. If there are total n samples we divide by n-1 instead of n:
=
sample variance
=
the value of the one observation
=
the mean value of observations
=
the number of observations
Correlation
Correlation measures the relationship between two variables.
We mentioned that a function has a purpose to predict a value, by converting input (x) to output (f(x)). We can say also say that a function uses the relationship between two variables for prediction.
Correlation Coefficient
The correlation coefficient is a value that indicates the strength of the relationship between variables. The coefficient can take any values from -1 to 1. The interpretations of the values are:
-1: Perfect negative correlation. The variables tend to move in opposite directions (i.e., when one variable increases, the other variable decreases).
0: No correlation. The variables do not have a relationship with each other.
1: Perfect positive correlation. The variables tend to move in the same direction (i.e., when one variable increases, the other variable also increases).
One of the primary applications of the concept in finance is portfolio management. A thorough understanding of this statistical concept is essential to successful portfolio optimization.
Correlation and Causation
Correlation must not be confused with causality. The famous expression “correlation does not mean causation” is crucial to the understanding of the two statistical concepts.
If two variables are correlated, it does not imply that one variable causes the changes in another variable. Correlation only assesses relationships between variables, and there may be different factors that lead to the relationships. Causation may be a reason for the correlation, but it is not the only possible explanation.
How to Find the Correlation?
The correlation coefficient that indicates the strength of the relationship between two variables can be found using the following formula:
Where:
rxy – the correlation coefficient of the linear relationship between the variables x and y
xi – the values of the x-variable in a sample
x̅ – the mean of the values of the x-variable
yi– the values of the y-variable in a sample
ȳ – the mean of the values of the y-variable
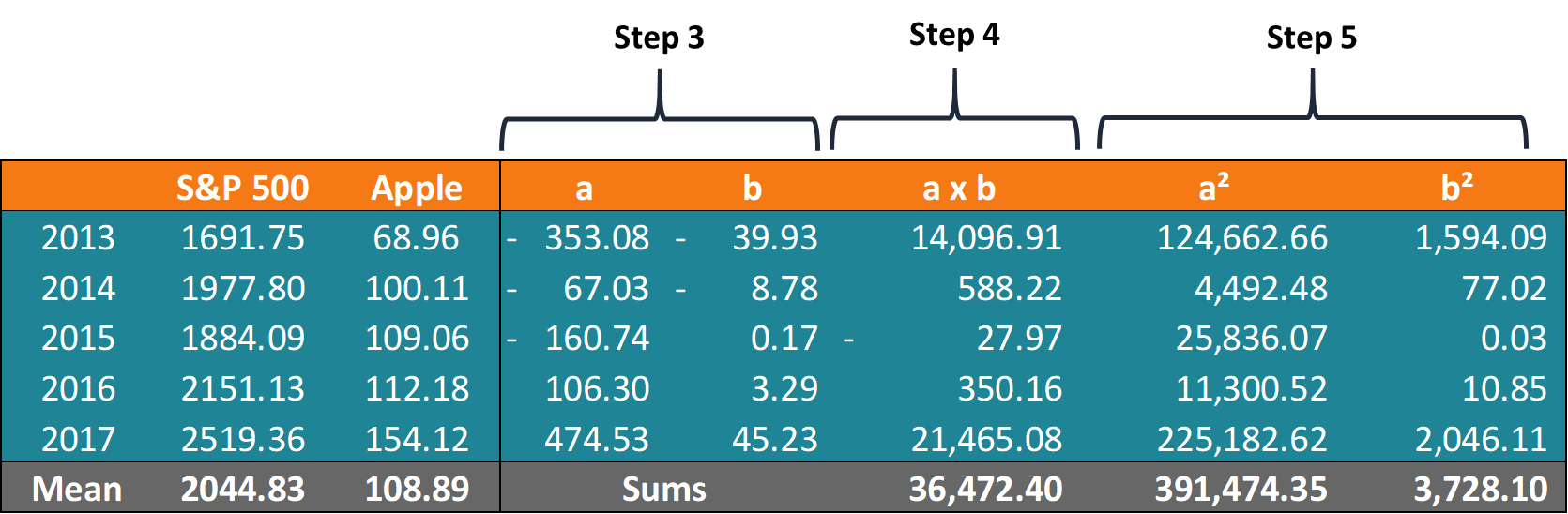
In order to calculate the correlation coefficient using the formula above, you must undertake the following steps:
Obtain a data sample with the values of x-variable and y-variable.
Calculate the means (averages) x̅ for the x-variable and ȳ for the y-variable.
For the x-variable, subtract the mean from each value of the x-variable (let’s call this new variable “a”). Do the same for the y-variable (let’s call this variable “b”).
Multiply each a-value by the corresponding b-value and find the sum of these multiplications (the final value is the numerator in the formula).
Square each a-value and calculate the sum of the result
Find the square root of the value obtained in the previous step (this is the denominator in the formula).
Divide the value obtained in step 4 by the value obtained in step 7.
You can see that the manual calculation of the correlation coefficient is an extremely tedious process, especially if the data sample is large. However, there are many software tools that can help you save time when calculating the coefficient. The CORREL function in Excel is one of the easiest ways to quickly calculate the correlation between two variables for a large data set.
Example of Correlation
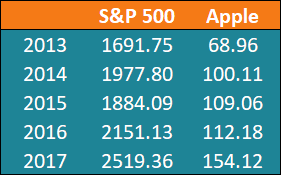
John is an investor. His portfolio primarily tracks the performance of the S&P 500 and John wants to add the stock of Apple Inc. Before adding Apple to his portfolio, he wants to assess the correlation between the stock and the S&P 500 to ensure that adding the stock won’t increase the systematic risk of his portfolio. To find the coefficient, John gathers the following prices for the last five years (Step 1):
Using the formula above, John can determine the correlation between the prices of the S&P 500 Index and Apple Inc.
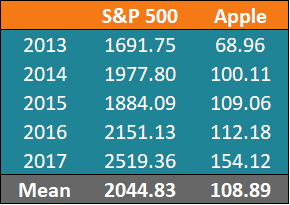
First, John calculates the average prices of each security for the given periods (Step 2):
After the calculation of the average prices, we can find the other values. A summary of the calculations is given in the table below:
Using the obtained numbers, John can calculate the coefficient:
The coefficient indicates that the prices of the S&P 500 and Apple Inc. have a high positive correlation. This means that their respective prices tend to move in the same direction. Therefore, adding Apple to his portfolio would, in fact, increase the level of systematic risk.
PROBABILITY:
What is Probability?
The concept of probability is extremely simple. It means how likely an event is about to occur or the chance of the occurrence of an event.
The formula for probability is:
For example:
The probability of the coin showing heads when it’s flipped is 0.5.
Conditional Probability
Conditional probability is the probability of an event occurring provided another event has already occurred.
The formula of conditional probability:
For example:
The students of a class have given two tests of the subject mathematics. In the first test, 60% of the students pass while only 40% of the students passed both the tests. What percentage of students who passed the first test, cleared the second test?
Bayes’ Theorem
Bayes’ Theorem is a very important statistical concept used in many industries such as healthcare and finance. The formula of conditional probability which we have done above has also been derived from this theorem.
It is used to calculate the probability of a hypothesis based on the probabilities of various data provided in the hypothesis.
The formula for Bayes’ theorem is:
=
events
=
probability of A given B is true
=
probability of B given A is true
=
the independent probabilities of A and B
For example:
Let’s assume there is an HIV test that can identify HIV+ positive patients accurately 99% of the time, and also accurately has a negative result for 99% of HIV negative people. Here, only 0.3% of the overall population is HIV positive.
Dependent and Independent Events
Dependent and Independent Events are the types of events that occur in probability. Suppose we have two events say Event A and Event B then if Event A and Event B are dependent events then the occurrence of one event is dependent on the occurrence of other events if they are independent events then the occurrence of one event does not affect the probability of other events.
We can learn about dependent and independent events with the help of examples such as the event of tossing two coins simultaneously the outcome of one coin does not affect the outcome of another coin then they are independent events. Suppose we take other experiments where we toss a coin only when we get a six in the throw of dice, where the outcome of one event is affected by other events then they are dependent events.
Dependent Events
Dependent events are those events that are affected by the outcomes of events that had already occurred previously. i.e. Two or more events that depend on one another are known as dependent events. If one event is by chance changed, then another is likely to differ. Thus, If whether one event occurs does affect the probability that the other event will occur, then the two events are said to be dependent.
When the occurrence of one event affects the occurrence of another subsequent event, the two events are dependent events. The concept of dependent events gives rise to the concept of conditional probability which will be discussed in the article further.
Examples of Dependent Events
For Example, let’s say three cards are to be drawn from a pack of cards. Then the probability of getting a king is highest when the first card is drawn, while the probability of getting a king would be less when the second card is drawn.
In the draw of the third card, this probability would be dependent upon the outcomes of the previous two cards. We can say that after drawing one card, there will be fewer cards available in the deck, therefore the probabilities after each drawn card changes.
Independent Events
Independent events are those events whose occurrence is not dependent on any other event. If the probability of occurrence of an event A is not affected by the occurrence of another event B, then A and B are said to be independent events.
Examples of Independent Events
Tossing a Coin
Sample Space(S) in a Coin Toss = {H, T}
Both getting H and T are Independent Events
Rolling a Die
Sample Space(S) in Rolling a Die = {1, 2, 3, 4, 5, 6}, all of these events are independent too.
Both of the above examples are simple events. Even compound events can be independent events. For example:
Tossing a Coin and Rolling a Die
If we simultaneously toss a coin and roll a die then the probability of all the events is the same and all of the events are independent events,
These events are independent because only one can occur at a time and occurring of one event does not affect other events.
Note
A and B are two events associated with the same random experiment, then A and B are known as independent events if
P(A ∩ B) = P(B).P(A)
Difference Between Independent Events and Dependent Events
The difference between independent events and dependent events is discussed in the table below,
Independent Events
Dependent Events
Independent events are events that are not affected by the occurrence of other events.
Dependent events are events that are affected by the occurrence of other events.
The formula for the Independent Events is,
P(A and B) = P(A)×P(B)
The formula for the Dependent Events is,
P(B and A) = P(A)×P(B after A)
Examples of Independent Events are,
Tossing one coin was not affected by the tossing of other coins
Raining for a day and getting six in dice are independent events.
Examples of Dependent Events are,
The probability of finding a red ball from a box of 4 red balls and 3 green balls changes if we take out two balls from the box.
Mutually Exclusive Events
Two events A and B are said to be mutually exclusive events if they cannot occur at the same time. Mutually exclusive events' never have an outcome in common. If we take two events A and B as mutually exclusive events where the probability of event A is P(A) and the probability of event B is P(B) then the probability of happening both events together is,
P(A∩B) = 0
Then the probability of occurring any one event is,
P(AUB) = P(A) or P(B) = P(A) + P(B)
Conditional Probability Formula
Conditional probability formula tells the formula for the probability of the event when an event has already occurred. If the probability of events A and B are P(A) and P(B) respectively then the conditional probability of B such that A has already occurred is denoted as P(A/B).
If P(A) > 0, then the P(A/B) is calculated by using the formula,
P(A/B) = P(A ∩ B)/P(A)
In the case of P(A) = 0 means A is an impossible event, in this case, P(A/B) does not exist.
Random Variables
A random variable in statistics is a function that assigns a real value to an outcome in the sample space of a random experiment. For example: if you roll a die, you can assign a number to each possible outcome.
Random variables can have specific values or any value in a range.
There are two basic types of random variables,
Discrete Random Variables
Continuous Random Variables
A random variable is considered a discrete random variable when it takes specific, or distinct values within an interval. Conversely, if it takes a continuous range of values, then it is classified as a continuous random variable.
Example of a Random Variable
A typical example of a random variable is the outcome of a coin toss. Consider a probability distribution in which the outcomes of a random event are not equally likely to happen. If the random variable Y is the number of heads we get from tossing two coins, then Y could be 0, 1, or 2. This means that we could have no heads, one head, or both heads on a two-coin toss.
However, the two coins land in four different ways: TT, HT, TH, and HH. Therefore, the P(Y=0) = 1/4 since we have one chance of getting no heads (i.e., two tails [TT] when the coins are tossed). Similarly, the probability of getting two heads (HH) is also 1/4. Notice that getting one head has a likelihood of occurring twice: in HT and TH. In this case, P (Y=1) = 2/4 = 1/2.
Random variables are generally represented by capital letters like X and Y. This is explained by the example below:
Example
If two unbiased coins are tossed then find the random variable associated with that event.
Solution:
Suppose Two (unbiased) coins are tossed
X = number of heads. [X is a random variable or function]
Here, the sample space S = {HH, HT, TH, TT}
Random Variable Definition
We define a random variable as a function that maps from the sample space of an experiment to the real numbers. Mathematically, Random Variable is expressed as,
X: S →R
where,
X is Random Variable (It is usually denoted using capital letter)
S is Sample Space
R is Set of Real Numbers
Suppose a random variable X takes m different values i.e. sample space
X = {x1, x2, x3………xm} with probabilities
P(X = xi) = pi
where 1 ≤ i ≤ m
The probabilities must satisfy the following conditions :
0 ≤ pi ≤ 1; where 1 ≤ i ≤ m
p1 + p2 + p3 + ……. + pm = 1 Or we can say 0 ≤ pi ≤ 1 and ∑pi = 1
Hence possible values for random variable X are 0, 1, 2.
X = {0, 1, 2} where m = 3
P(X = 0) = (Probability that number of heads is 0) = P(TT) = 1/2×1/2 = 1/4
P(X = 1) = (Probability that number of heads is 1) = P(HT | TH) = 1/2×1/2 + 1/2×1/2 = 1/2
P(X = 2) = (Probability that number of heads is 2) = P(HH) = 1/2×1/2 = 1/4
Here, you can observe that, (0 ≤ p1, p2, p3 ≤ 1/2)
p1 + p2 + p3 = 1/4 + 2/4 + 1/4 = 1
For example,
Suppose a dice is thrown (X = outcome of the dice). Here, the sample space S = {1, 2, 3, 4, 5, 6}. The output of the function will be:
P(X=1) = 1/6
P(X=2) = 1/6
P(X=3) = 1/6
P(X=4) = 1/6
P(X=5) = 1/6
P(X=6) = 1/6
Variate
A variate is a generalization of the concept of a random variable that is defined without reference to a particular type of probabilistic experiment.
It has the same properties as random variables and is denoted by capital letters (commonly X).
The possible values a random variable X can take are its range, denoted R_X. Individual values within this range are called quantiles, and the probability of X taking a specific value x is written as P(X=x).
Types of Random Variable
Random variables are of two types that are,
Discrete Random Variable
Continuous Random Variable
Discrete Random Variable
A discrete random variable can take only a finite number of distinct values such as 0, 1, 2, 3, 4, … and so on. The probability distribution of a random variable has a list of probabilities compared with each of its possible values known as probability mass function.
In an analysis, let a person be chosen at random, and the person’s height is demonstrated by a random variable. Logically the random variable is described as a function which relates the person to the person’s height. Now in relation with the random variable, it is a probability distribution that enables the calculation of the probability that the height is in any subset of likely values, such as the likelihood that the height is between 175 and 185 cm, or the possibility that the height is either less than 145 or more than 180 cm. Now another random variable could be the person’s age which could be either between 45 years to 50 years or less than 40 or more than 50.
Continuous Random Variable
A numerically valued variable is said to be continuous if, in any unit of measurement, whenever it can take on the values a and b. If the random variable X can assume an infinite and uncountable set of values, it is said to be a continuous random variable. When X takes any value in a given interval (a, b), it is said to be a continuous random variable in that interval.
Formally, a continuous random variable is such whose cumulative distribution function is constant throughout. There are no “gaps” in between which would compare to numbers which have a limited probability of occurring. Alternately, these variables almost never take an accurately prescribed value c but there is a positive probability that its value will rest in particular intervals which can be very small.
Random Variable Formula
For a given set of data the mean and variance random variable is calculated by the formula. So, here we will define two major formulas:
Mean of random variable
Variance of random variable
Mean of random variable: If X is the random variable and P is the respective probabilities, the mean of a random variable is defined by:
Mean (μ) = ∑ XP
where variable X consists of all possible values and P consists of respective probabilities.
Variance of Random Variable: The variance tells how much is the spread of random variable X around the mean value. The formula for the variance of a random variable is given by;
Var(X) = σ2 = E(X2) – [E(X)]2
where E(X2) = ∑X2P and E(X) = ∑ XP
Functions of Random Variables
Let the random variable X assume the values x1, x2, …with corresponding probability P (x1), P (x2),… then the expected value of the random variable is given by:
Expectation of X, E (x) = ∑ x P (x).
A new random variable Y can be stated by using a real Borel measurable function g:R→R, to the results of a real-valued random variable X. That is, Y = f(X). The cumulative distribution function of Y is then given by:
FY(y) = P(g(X)≤y)
If function g is invertible (say h = g-1 )and is either increasing or decreasing, then the previous relationship can be extended to obtain:
Now if we differentiate both the sides of the above expressions with respect to y, then the relation between the probability density functions can be found:
fY(y) = fx(h(y))|dh(y)/dy|
Random Variable and Probability Distribution
The probability distribution of a random variable can be
Theoretical listing of outcomes and probabilities of the outcomes.
An experimental listing of outcomes associated with their observed relative frequencies.
A subjective listing of outcomes associated with their subjective probabilities.
The probability of a random variable X which takes the values x is defined as a probability function of X is denoted by f (x) = f (X = x)
A probability distribution always satisfies two conditions:
f(x)≥0
∑f(x)=1
The important probability distributions are:
Binomial distribution
Poisson distribution
Bernoulli’s distribution
Exponential distribution
Normal distribution
Continuous Probability Distributions
Continuous probability distribution: A probability distribution in which the random variable X can take on any value (is continuous). Because there are infinite values that X could assume, the probability of X taking on any one specific value is zero. Therefore we often speak in ranges of values (p(X>0) = .50). The normal distribution is one example of a continuous distribution. The probability that X falls between two values (a and b) equals the integral (area under the curve) from a to b:
A normal distribution is a type of continuous probability distribution in which most data points cluster toward the middle of the range, while the rest taper off symmetrically toward either extreme. The middle of the range is also known as the mean of the distribution.
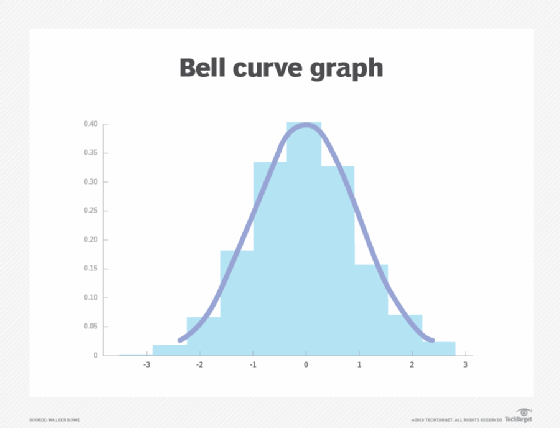
The normal distribution is also known as a Gaussian distribution or probability bell curve. It is symmetric about the mean and indicates that values near the mean occur more frequently than the values that are farther away from the mean.
Normal distribution explained
Graphically, a normal distribution is a bell curve because of its flared shape. The precise shape can vary according to the distribution of the values within the population. The population is the entire set of data points that are part of the distribution.
Regardless of its exact shape, a normal distribution bell curve is always symmetrical about the mean. A symmetrical distribution means that a vertical dividing line drawn through the maximum/mean value will produce two mirror images on either side of the line, in which half the population is less than the mean and half is greater. However, the reverse is not always true; that is, not all symmetrical distributions are normal. In the bell curve, the peak is always in the middle, and the mean, mode and median are all the same.
A normal distribution bell curve is always symmetrical about the mean.
Basic examples of normal distribution: Height and weight
Height is one simple example of values that follow a normal distribution pattern. Most people are of average height -- whatever that may be for a given population. If the heights of these people are represented in graphical format along with the heights of people who are taller and shorter than the average, the distribution will always be a normal distribution. This is because the people of average height will be clustered near the middle, while those who are taller and shorter will be farther away.
Further, these latter groups will consist of very small numbers of people. The number of people who are extremely tall or extremely short will be even smaller, so they will be the farthest away from the mean.
Similarly, weight can also follow a normal distribution if the average weight of the population under consideration is known. Like height, the weight outliers will be those who weigh more or less than the average. The bigger the deviation from the average, the farther away those data points will be on the distribution graph.
Importance of normal distribution
The normal distribution is one of the most important probability distributions for independent random variables for three main reasons.
First, normal distribution describes the distribution of values for many natural phenomena in a wide range of areas, including biology, physical science, mathematics, finance and economics. It can also represent these random variables accurately.
In addition to height and weight, normal distributions are also used to represent many other values, including the following:
measurement error
blood pressure
IQ scores
asset prices
price action
Second, the normal distribution is important because it can be used to approximate other types of probability distribution, such as binomial, hypergeometric, inverse (or negative) hypergeometric, negative binomial and Poisson distribution.
Third, normal distribution is the key idea behind the central limit theorem, or CLT, which states that averages calculated from independent, identically distributed random variables have approximately normal distributions. This is true regardless of the type of distribution from which the variables are sampled, as long as it has finite variance.
Normal distribution formula and empirical rule
The formula for the normal distribution is expressed below.
The formula for the normal distribution.
Here, x is value of the variable; f(x) represents the probability density function; μ (mu) is the mean; and σ (sigma) is the standard deviation.
The empirical rule for normal distributions describes where most of the data in a normal distribution will appear, and it states the following:
68.2% of the observations will appear within +/-1 standard deviation of the mean;
95.4% of the observations will fall within +/-2 standard deviations; and
99.7% of the observations will fall within +/-3 standard deviations.
All data points falling outside of three standard deviations (3σ) indicate rare occurrences.
Parameters of normal distribution
Since the mean, mode and median are the same in a normal distribution, there's no need to calculate them separately. These values represent the distribution's highest point, or the peak. All other values in the distribution then fall symmetrically around the mean. The width of the mean is defined by the standard deviation.
In fact, only two parameters are required to describe a normal distribution: the mean and the standard deviation.
1. The mean
The mean is the central highest value of the bell curve. All other values in the distribution either cluster around it or are at some distance away from it. Changing the mean on a graph will shift the entire curve along the x-axis, either toward the left or toward the right. However, its symmetricity will still be maintained.
2. The standard deviation
In general, standard deviation is a measure of variability in a distribution. In a bell curve, it defines the width of the distribution and shows how far away from the mean the other values fall. In addition, it represents the typical distance between the average and the observations.
Changing the standard deviation will change the distribution of values around the mean. A smaller deviation will reduce the spread -- tightening the distribution -- while a larger deviation will increase the spread and produce a wider distribution. As the distribution gets wider, it becomes more likely that values will be farther away from the mean.
Central Limit Theorem
The central limit theorem states that whenever a random sample of size n is taken from any distribution with mean and variance, then the sample mean will be approximately a normal distribution with mean and variance. The larger the value of the sample size, the better the approximation of the normal.
Assumptions of the Central Limit Theorem
The sample should be drawn randomly following the condition of randomization.
The samples drawn should be independent of each other. They should not influence the other samples.
When the sampling is done without replacement, the sample size shouldn’t exceed 10% of the total population.
The sample size should be sufficiently large.
Formula
The formula for the central limit theorem is given below:
Proof
Consider x1, x2, x3,……,xn are independent and identically distributed with mean μ and finite variance σ2, then any random variable Zn as,
Here,
Then, the distribution function of Zn converges to the standard normal distribution function as n increases without any bound.
Again, define a random variable Ui by
E(Ui) = 0 and V(Ui) = 1
Thus, the moment-generating function can be written as
Also,
Since xi are random independent variables, Ui are also independent.
This implies,
As per Taylor series expansion:
,
Which is the moment-generating function for a standard normal random variable.
Steps
The steps used to solve the problem of the central limit theorem that are either involving ‘>’ ‘<’ or “between” are as follows:
1) The information about the mean, population size, standard deviation, sample size and a number that is associated with “greater than”, “less than”, or two numbers associated with both values for a range of “between” is identified from the problem.
2) A graph with a center as the mean is drawn.
3)
4) The z-table is referred to find the ‘z’ value obtained in the previous step.
5) Case 1: Central limit theorem involving “>”.
Subtract the z-score value from 0.5.
Case 2: Central limit theorem involving “<”.
Add 0.5 to the z-score value.
Case 3: Central limit theorem involving “between”.
Step 3 is executed.
6) The z-value is found along with the x-bar.
The last step is common to all three cases, that is, to convert the decimal obtained into a percentage.
Vision of the Institution "To create a collaborative academic environment to foster professional excellence and ethical values" Mission of the Institution To develop outstanding professionals with high ethical standards capable of creating and managing global enterprises To foster innovation and research by providing a stimulating learning environment To ensure equitable development of students of all ability levels and backgrounds To be responsive to changes in technology, socio-economic and environmental conditions To foster and maintain mutually beneficial partnerships with alumni and industry Vision of the Department To Nurture professionals in the field of Artificial Intelligence and Machine Learning by disseminating knowledge and skills in the area of Artificial Intelligence and Machine Learning and inculcate into them social and ethical values towards serving the greater cause of the society Mission of the Department M1: To foster students with the latest technologie...


















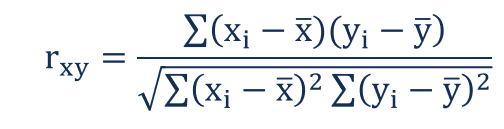
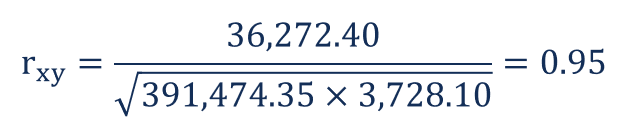
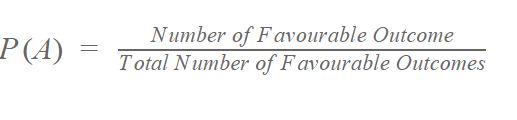
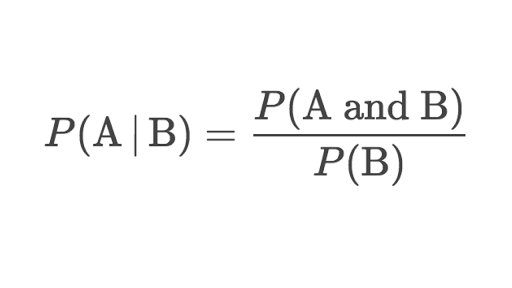







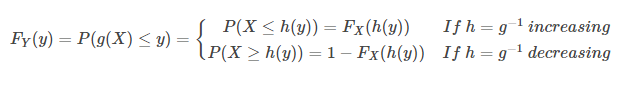


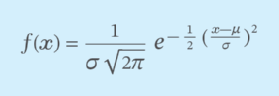

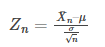
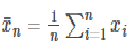
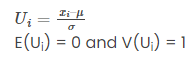
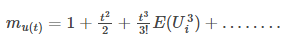
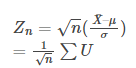
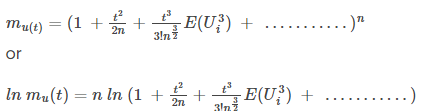
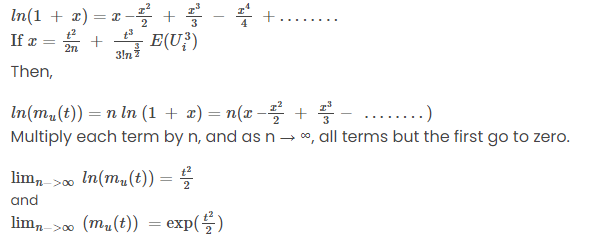
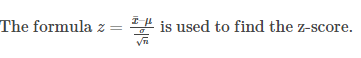
Comments
Post a Comment